
Updated severity spreadsheet lets collision repairers find true shop-specific average, justify KPI deviation
By onBusiness Practices | Education | Insurance | Repair Operations
When an insurer calls your collision repair shop out for being over a particular estimate severity level, remember two things before you apologize:
- Severity is uncontrollable. Unless one of you goes out and instigates wrecks, there’s no way to know what’s going to come in your lot each day.
- A national severity average might be very different than your shop’s severity average, based on vehicle mix.
We’ll start with the easy one. While insurers and repairers can do their best to estimate severity, it’s not a normal distribution like human height probability and certainly not something a collision repairer with a KPI can truly manage.
It’s a chaotic value, influenced by largely uncontrollable variables like weather, OEM design refreshes and model generations, the economy, government safety and environmental edicts, consumer preferences and flat out human driver unpredictability — and for a collision repair, that particular local market.
Just like the stock market, past performance in severity is no guarantee of future results. No amount of pointing to a computer model will change a car limping into your lot with $5,000 worth of damage into one that matches a $2,500 average so you hit your KPI. Black swans will happen.
“They’re (insurers) trying to artificially manage severity, which is a relatively non-manageable number given the small sample size most shops are judged on,” Tim Ronak, senior services group consultant for AkzoNobel’s North America automotive and aerospace coatings, wrote in an email. In an earlier interview, he likened judging a shop on their severity performance “like arguing that it’s too hot because the sky is blue.”
That said, just as with the stock market, there’s still a few lessons to be gained from severity data. After all, insurers have built a business on how well they can predict the unpredictable, and collision repairers can not only do the same but debate severity with insurers on their own terms.
AkzoNobel at Repairer Driven Education
Those wanting to learn more from AkzoNobel should check out “Getting Paid for Investing in Facility, Equipment and Training” with Tim Ronak and “The Myths, Mysteries and Fallacies Surrounding Accurate Repair Planning” with Bob Gilbert. The presentations will be at this year’s SEMA Show as part of the Society of Collision Repair Specialists’ Repairer Driven Education series. Register here.
“I believe 2016 is going to be the year of severity,” Ronak said, arguing that insurers will look hard at cutting costs in addition to premium increases to improve smaller than desired current underwriting profits.
“Cost minimization is always a strategy, and they’re very, very good at it,” he said.
He called it the “whack-a-mole style” of direct repair program management, whacking auto body shops above the average one after after another until the average itself is lowered.
You’ll notice, Ronak observed, that a shop coming in below the average won’t ever be told they’re not charging enough or itemizing enough work on damaged cars.
Average severity
Ronak said the key to determining your own shop’s severity — which can be vastly different from the nationwide average severity — can be found in the Insurance Institute for Highway Safety’s loss data. For years, he has been compiling the data into a sortable Excel spreadsheet as an industry resource.
“It’s really difficult to get it from the website into that tool,” he said.
His latest version draws on the most current IIHS Highway Loss Data Institute data regarding 2011-13 model losses across multiple lines. The organization uses real claim information from the nation’s largest insurers in both collision and catastrophic lines to indicate which models rack up higher claim bills.
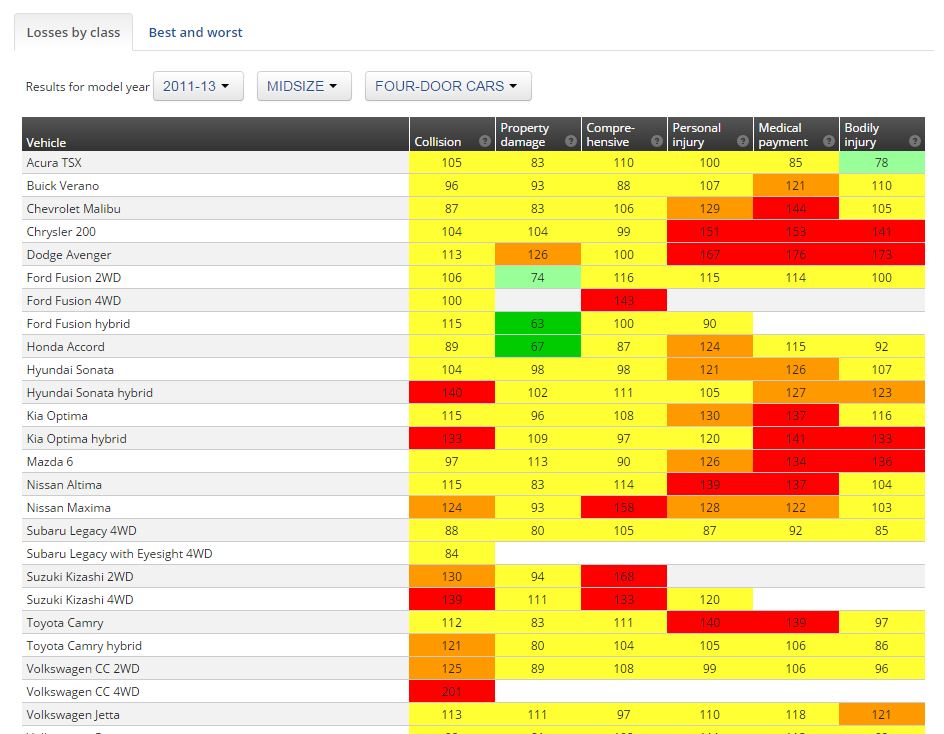
The IIHS essentially grades the damage incurred by those models through early 2014 on a curve. Like other governmental statistical comparison models, it uses a base 100 system of comparison which sets the average equal to 100 and represents amounts above and below that “base” accordingly.
A score of 100 in collision for a particular model year means the car’s average collision repair claim equaled the average dollar amount observed by the entire American fleet. A model with collision claims 10 percent higher than average would be rated 110, while one with bills 10 percent lower than average would receive a 90 score.
Using real IIHS data: The four-door Volkswagen Jetta’s score of 113 means its average losses should be 13 percent higher than the average overall severity for that data set. The four-door Honda Civic’s 94 means its repairs should cost 6 percent lower than that same average value.
Virtually anything you can think of is included in the database; the IIHS’ highest collision score was a two-door Ferrari 458 Italia at 546, or 446 percent above whatever the average bill was.
For context, Mitchell’s data found the first-quarter 2014 collision bill averaged $3,164.
Not surprisingly, the highest severity vehicles are all luxury and sports cars. After that tends to fall smaller vehicles. The lower-severity-averaging vehicles tend to be trucks.
“It seems that severity is tied to vehicle size and smaller vehicles tend to have a higher severity where larger vehicles tend to have lower severity,” Ronak wrote. “With a swing to smaller more efficient vehicles severity values are likely to increase not due to charging more but rather due to the intrinsic characteristics that an increased number of smaller cars on the road exposed to damage will cost more per unit to repair.”
How to use it
Such information allows you to gauge whether you’re fitting into an appropriate range of repair bills.
This can be done using a process best demonstrated with an excercise prepared by Ronak. Follow along or try it yourself at home using the data broken out starting at Row 582 of the second sheet (“Sortable Data 2011-2013”) in Ronak’s Excel file.
A hypothetical shop sees a repair mix of 50 percent Mercedes models, 20 percent Acura models and 30 percent Dodge models. Taking the average severity for all three makes on the IIHS scale leaves Mercedes with an average of 189, Acura with an average of 98 and Dodge with an average of 104.
Weight the three makes’ averages by their proportion in your shop and add those values together.
(0.5 X 189) + (0.20 X 98) + (0.30 X 104) = 94.5 + 19.6 + 31.2 = 145.3
The average severity for that shop, based on repair mix, should be 45.3 percent higher than the average.
In non-algebra professor terms: Let’s say an insurer questions why that shop’s severity on a single repair bill or a longer-term KPI is $3,700. After all, using the $3,164 Mitchell average collision severity discussed earlier, the shop appears to be a few hundred dollars over where they should be.
Many shops “basically say, ‘I’m sorry'” and look for ways to reduce severity, such as eliminating billing for operations or looking for cheaper parts or resources, according to Ronak.
“The data is being used to coerce them,” he said.
But by calculating their severity along the lines he recommended, that shop’s estimator or owner can retort that they’re actually saving the insurer money. 145.3 percent of $3,164 is about $4,597, far below the current $3,700 they were initially told was too high.
Ronak said that using the average for a make generally is enough to make your point to an insurer, though of course you could calculate based on the precise mix of models in this fashion, he said.
This example only uses the 2011-13 model year range, and the IIHS cautions against extrapolating to past ranges given automotive redesigns. But that cuts both ways: What data set is your insurer basing their severity number upon? If the guy bothering you for not meeting the KPI doesn’t know, you’re already on your way to winning an argument.
If you wanted to do the math yourself using a mix of age ranges, you could. (Ask Ronak or somebody better than math than Repairer Driven News for assistance.) Since the average collision-claim vehicle was about seven years old in early 2014 (and even today), you should be able to work out most of your repair mix using the IIHS data, which stretches back on an apples-to-apples basis to the 2004-06 model years. Ronak’s already compiled most of those stretches into the most current database.
“I’m frustrated that collision centers are being managed by their vendor partners through incomplete assessment of the factor they are being evaluated on,” Ronak wrote.
Even if you were a miracle shop which somehow proportionally repaired the exact average mix of cars on the road, you could still exceed the average severity without deserving a KPI spanking. That’s because of the concept of “natural variability” of data around a mean (average), according to Ronak.
Most shops aren’t going to be repairing 1,000 cars a month or any number which would be expected to closely follow the mean, and as a result they need to “quantify the quality of that sample data pool and how closely it follows a natural Normal Distribution,” according to Ronak.
There’s going to be a natural variance in how well a particular data point stacks up against the average, known as the standard deviation. (It’s not exactly an MIT statistics Ph.D thesis, but the education resource MathIsFun.com offers a good layman description.)
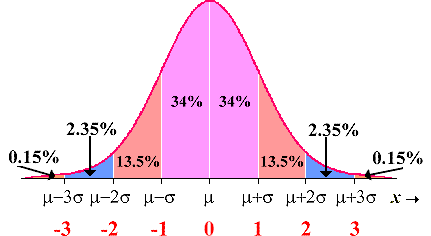
Generally, in a normal distribution of data with a large enough sample size, about 68.2 percent of shops’ values will fall within a single standard deviation — 34.1 percent of them higher than average, 34.1 percent of them lower than average.
“Depending on the sample size it could be a narrow or wide variance and any discussion of an average should ALSO include a discussion on how far above and below one standard deviation is in Dollars,” Ronak wrote. “Typically the smaller the sample size is from 1000 data points the wider and more erratic the standard deviation can be. When was the last time you repaired 1000 units for the same carrier in one month?”
So when your adjuster or other insurance partner complains about your KPI, ask whether you’re within a standard deviation of their data set and ask to see their data. If they can’t or won’t provide the foundation for their level, you’ve got leverage.
Being ready to make such arguments as described here will require effort on a shop’s part, though the IIHS and Ronak have done much of the work for you. But when it’s a question of hundreds of dollars more allowed on repair bills and an end to severity arguments, it behooves shops to perform the relatively simple Excel work.
“It takes it (severity) off the table,” Ronak said.
Images:
There’s no way to truly guarantee what damage level of vehicles will enter your collision repair shop. (RobertCrum/iStock/Thinkstock)
IIHS Highway Loss Data Institute data regarding 2011-13 model losses indicates which models could rack up high claim bills using a base 100 system. (Screenshot from www.iihs.org)
Generally, more than 68 percent of values will fall within a single standard deviation — 34.1 percent of them higher than average, 34.1 percent of them lower than average. (Provided by NASA Earth Observatory project)